

Keep up with the demands of accurate data extraction and validation from unstructured data like PDFs or images of invoices, receipts, forms and other documents is a mounting challenge in most large enterprises today.
Finding a solution to address this problem is crucial. It has the power to significantly improve operational efficiency, boost your top line, and give you a competitive edge. Additionally, it will enhance the customer experience, further solidifying your position in the market.
Imagine the freedom to focus on strategic initiatives while tasks like invoice data extraction, KYC verification, remittance processing, and bank loan disbursement are handled effortlessly.
Join the ranks of retail and financial institutions in the EU, UAE, and India who are already experiencing exceptional results. They have witnessing remarkable improvement in efficiency and output with our AI-powered platform, DocExtractor.
At Docextrcator, we use cutting-edge technology like GPT-4’s advanced natural language processing capabilities to extract text and data from PDF documents or images, including tables, forms, header, footer and so on.
GPT-4 is a large language model (LLM) developed by OpenAI. Among the most potent LLMs globally, it comprehends and generates human-quality text effortlessly. Say goodbye to laborious manual data analysis and categorization of PDFs, as GPT-4 streamlines the process, unlocking boundless productivity gains.
In this in-depth blog on LLM, we will explore,
- Methods of PDF data extraction
- About GPT – 4 and ChatGPT
- How we can help you to extract data from documents and images in scale
Let’s get started.
What is PDF Data Extraction?
PDF extraction using GPT-4 LLM Model is the process of extracting data from a PDF file, which includes text, tables, graphs, and other types of content.
The important reasons for using PDF data extraction with GPT-4 include:
Accessibility: PDFs are often used by people with disabilities, such as those who are blind or have low vision. PDF extraction can make these documents more accessible by converting them into a format that can be read by screen readers or other assistive technology.
Data analysis: PDFs can contain a lot of valuable data, such as product information, customer data, or financial data. PDF extraction can make this data easier to analyze by converting it into a format that can be imported into a spreadsheet or database.
Reusing content: PDFs often contain content that is useful in other documents. For example, you might want to extract the table of contents from a PDF and insert it into a presentation. PDF extraction can make it easy to reuse content from PDFs in other documents.
In the legal industry, it’s used to extract data from legal documents like contracts, pleadings, and case files. This data can then be used to analyze trends, identify potential risks, and streamline legal workflows.
On the other hand, in the financial industry, PDF extraction is used to extract data from financial documents like invoices, receipts, and investment statements. This data can then be used to reconcile accounts, track expenses, and manage investments.
Methods of PDF Data Extraction:
Machine Learning Techniques:
In the early days of PDF extraction, people used to manually extract data from PDF files. This was a tedious and time-consuming process, and it was prone to errors. Then, machine learning came along and changed everything. Machine learning (ML) PDF data extraction allows highly accurate text recognition and extraction from PDF files regardless of the file structure. Machine Learning with LLM models can store both layout’ and text position’ information, taking into account neighboring text.
Basically, LLMs are trained on massive datasets of text, and they can learn to understand the context of the text they are processing. In the next step, they generate a sensible context for the extracted text. This context can then be used to help the model identify any errors in the extraction.
For example, if an LLM is trained on a dataset of scientific papers, it will learn to understand the conventions used in scientific papers. This means whenever it comes to data extraction in scientific papers, it can understand the missing data and errors.
OCR Technique:
OCR, or Optical Character Recognition, is a technology that can be used to extract text from a variety of sources, including scanned documents, images, and PDF files. OCR is commonly used to digitize printed documents such as books, newspapers, and historical documents.
It can be used for:
- Extracting text from scanned documents.
- Automatically extracting and processing data from forms.
- Extracting text from images for machine learning or natural language processing.
Some popular OCR tools and Python libraries include:
- PyTesseract Module
- EasyOCR
- Keras-OCR
Template-Based:
Template-based techniques for extracting data from PDFs use hard-coded rules to identify specific patterns in the text. These techniques are generally well-suited for structured documents, such as invoices or purchase orders, where the layout of the document is consistent from one instance to the next.
What is GPT-4 and ChatGPT?
GPT-4 and ChatGPT are both large language models (LLMs) created by OpenAI. LLMs are a type of artificial intelligence (AI) that is trained on massive datasets of text and code. The Generative AI under the GPT-4 model allows us to generate text, translate languages, generate images, answer questions, and perform many other tasks.
GPT-4 is the most recent generation of LLMs from OpenAI. It has been trained on a dataset of text and code that is 45 gigabytes in size, which is significantly larger than the dataset used to train GPT-3. This makes GPT-4 more powerful and capable than GPT-3, and it can generate text that is more accurate, creative, and informative.
Here is a glimpse into the model architecture:
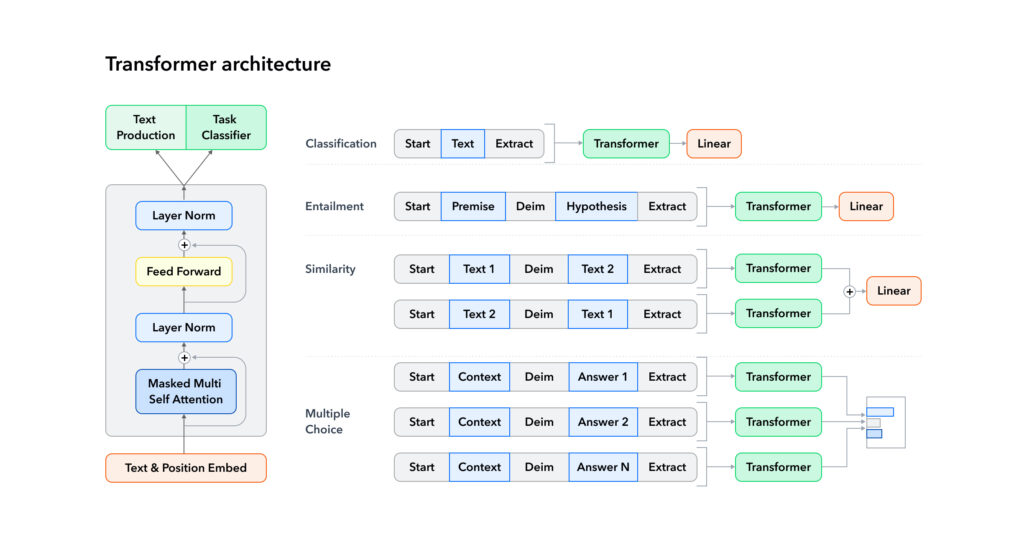
How Docextractor Uses GPT-4 LLM for PDF Data Extraction?
Enterprise Process Flow for PDF Data Extraction:
Step #1: Data Acquisition and Client Consultation
- Extract PDF Files: The process begins with extracting the required PDF files from the provided zip archives.
- Client Consultation: We schedule a meeting with the client to understand their specific data extraction requirements. During this meeting, we ensure clarity on the data to be extracted and assess the quality of the PDF files.
- Pre-processing: Once we have the PDF files, we conduct pre-processing to ensure the images are of the required quality for accurate data extraction.
Step #2: Data Annotation and Preparing Key-Value Pairs
- Data Annotation: Our expert team employs a combination of artificial intelligence and manual methods to extract the necessary data from the PDF files. This involves annotating the images to identify different data elements.
- Key-Value Pairing: To facilitate machine learning, we extract data in key-value pairs. Each element in the images is carefully labeled with its corresponding key-value pair. For instance, product names, prices, and descriptions are accurately annotated.
Step #3: Utilizing GPT-4 Model for Data Extraction
- Leveraging GPT-4: Our advanced GPT-4 language model, trained on an extensive dataset of text and code, is employed for data extraction. GPT-4’s capabilities in text generation and understanding context enable it to excel in data extraction tasks.
- JSON Code Integration: The annotated data is transformed into JSON code, representing the relationships between different keywords.
- GPT-4 Data Extraction: The JSON code is passed to the GPT-4 model, which rapidly learns the relationships between keywords and uses its training knowledge to extract the data accurately.
- Automatic Data Extraction: By leveraging GPT-4’s capabilities, our model automatically develops the ability to extract data from PDFs, streamlining further processing of PDF documents.
Throughout this process, our dedicated team, led by our CTO Ananya Nayan Boorah, ensures meticulous attention to detail and quality control. We continually enhance our data extraction model to adapt to varying PDF formats and cater to the unique requirements of our clients.
As a result of our efficient and effective PDF data extraction process, our enterprise clients, including reputable brands like MMK Accounting and Auditing, and VET Control, have experienced enhanced data analysis, improved workflows, and increased accessibility of PDF documents. If you are seeking reliable and accurate PDF data extraction services, do not hesitate to contact us for a seamless experience.